Current businesses are dynamic, so the data generated. Conventional RDBMS systems may face challenges hosting and analyzing this data, in this blog we see how I can make use of modern platforms and process data efficiently and with cost in mind.
Let’s start understanding the requirements from the customer and start modelling.
Requirement 1: Human resources department in company “X” needs to build and maintain a database to maintain their employee details, pay history etc.
Requirement 2: Finance department needs to build and maintain a database to maintain their sales performance data.
Common requirements to consider from their office of CTO:
- They plan to integrate multiple departments and project this as a centralized single source of truth in future, so scalability is key.
- Should be format independent to be flexible to customize as per the client requirement.
- Solution ideal for analytical processing than transactional processing. They don’t plan to retire their conventional relational system anytime sooner.
- Cost effective, at this moment features like High Availability, Replication are not needed and prefer to avoid saving few $. Cloud solution is ideal.
Considering all the points listed I will demonstrate how this can be accomplished using “Azure Synapse Serverless Lake Database“.
“Perhaps I will write how to implement this in Databricks lake house next time.”
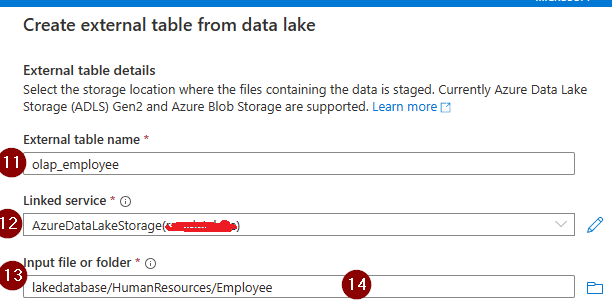
A lake database is a virtual database created on Azure synapse workspace which points to one or more file storage beneath. (Database itself doesn’t store any user data in their table). To further understand I recommend referring. https://learn.microsoft.com/en-us/azure/synapse-analytics/media/metadata/shared-databases.png
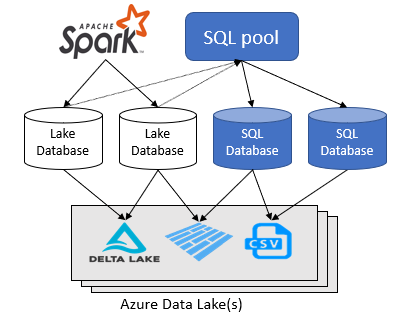{kind=link}
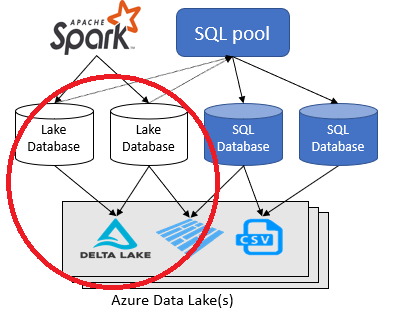
Here I am implementing the structure encircled in red above.
Assumptions:
- You already have a data lake with data loaded for HR data. (Parquet, csv etc..). If not, your primary focus should be to fetch data and store it in azure data lake. You may use adf pipeline or any ETL framework to extract, curate and load.
- You already have an Azure synapse workspace and connection (linked service) established to the lake.
Let’s build schema for their HR data which is a best candidate for external table due to the reason that data is not very volatile and in fact the underlying data will get refreshed by an ETL/ELT pipeline every night.
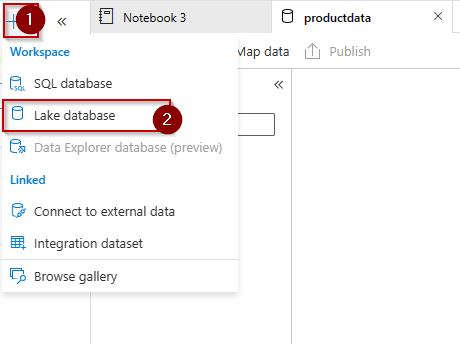
Step 1: Create a lake database.
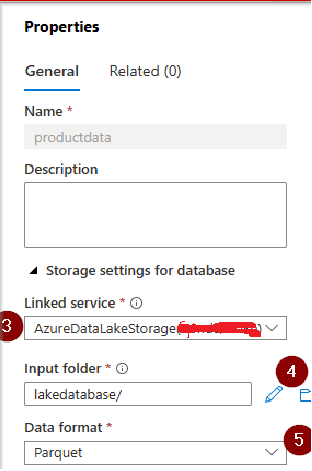
Step 2: Define the linked service for your data source and the format of the file for the purpose of lake database creation. (Please note this can be changed later for every table you create)
Step 3: Create Lake database table out of the data reside in your lake.
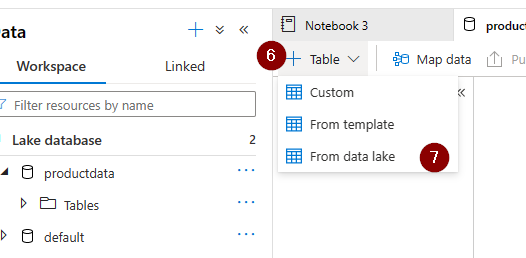
Tip: Partitioning your data in data lake is key here. Polybase do support wildcards.
Step 4: Point table to your source data lake directory
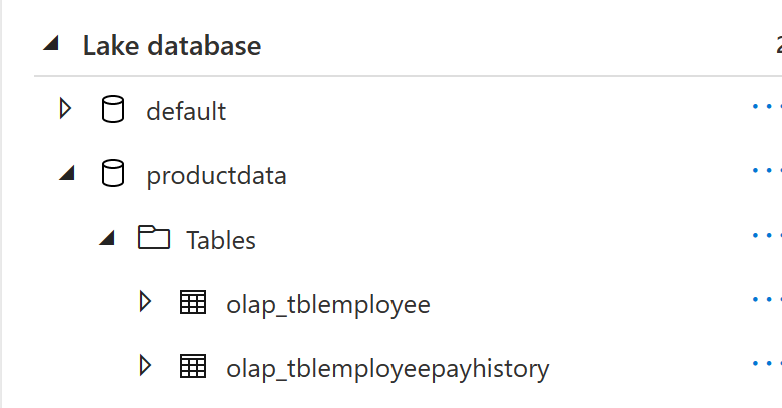
If all above steps are followed you should see the tables in your azure synapse lake database.
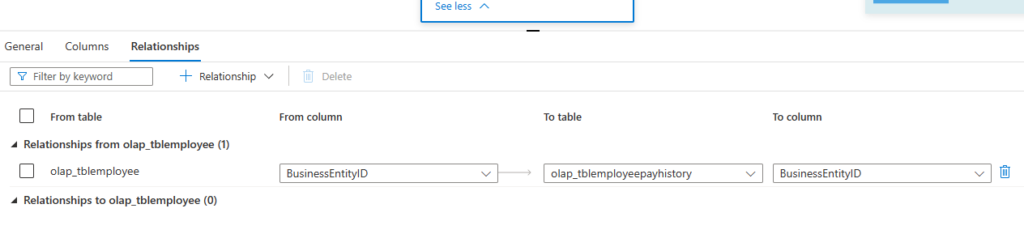
Tip: You can even set the relationship between tables for the purpose of data diagram.
Let’s query the tables created with basic SQL with joins.
SELECT te.JobTitle,te.LoginID,eh.rate,eh.payfrequency FROM [productdata].[dbo].[olap_tblemployee] te join [productdata].[dbo].[olap_tblemployeepayhistory] eh on te.businessentityid=eh.businessentityid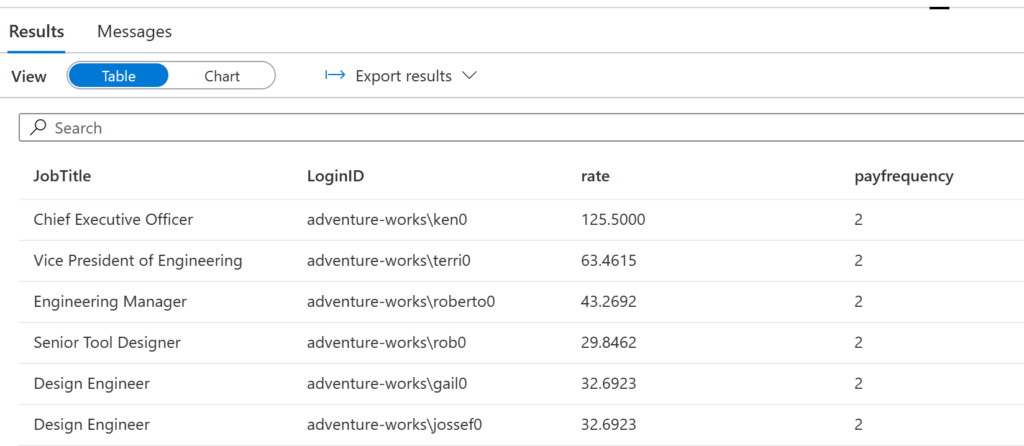
There you are.!!!
The “dbo” schema is reserved for the lake tables that are originally created in Spark or database designer. Hence don’t forget to call the three-part name of the object.
Now it’s time for building schema for the volatile data owned by finance department. For this , first we must create a “delta” lake. Delta lake is an abstract layer on top of my azure data lake. I chose delta lake for my volatile data due to it supportability of ACID transactions, data manipulation language including upsert and update, data integrity, streaming etc. (always finance department needs something additional out of their money…lol)
Assumptions:
- You already have a data lake with data loaded for finance data. (Parquet, csv etc..). If not, your primary focus should be to fetch data and store it in azure data lake. You may use adf pipeline or any ETL framework to extract, curate and load.
Step 1: Build a “delta lake” on my azure “data lake”.
–loading data into data frame from a parquet
%%pyspark
df = spark.read.load('abfss://[email protected]/staging/SalesOrderHeader/SalesOrderHeader.parquet',
format='parquet',header=True)–define delta location and save the data frame as delta
delta_table_path = "abfss://[email protected]/Sales/delta/SalesOrderHeader"
df.write.format("delta").save(delta_table_path)Step 2: It’s time to define the schema on top of delta lake. I prefer SQL for keeping it simple.
–create table from the delta location, point to the directory.
%%sql
CREATE TABLE productdata.oltp_SalesOrderHeader
USING DELTA
Location 'abfss://[email protected]/Sales/delta/SalesOrderHeader'If above steps are followed you should see the tables in your azure synapse lake database. (I created two tables for demo)
Step 3: Here are few sample queries to select, update, insert operations.
%%sql
--update the table the way you want, just like a SQL table
UPDATE productdata.oltp_salesorderheader
SET status = 7 WHERE status = 5;
select * from productdata.oltp_salesorderheader
--insert a value into the table
insert into productdata.oltp_SalesOrderHeader
values(43659,1,'4911-403C-98',1,776,1,2024.994,0.00,2024.994000,'B207C96D-D9E6-402B-8470-2CC176C42283','2011-05-31 00:00:00.000')
-- filtering
select * from productdata.oltp_SalesOrderDetail
WHERE SalesOrderID = 43659
-- joining two tables
SELECT sd.SalesOrderID,sd.orderqty,sh.status,sh.DueDate
FROM [productdata].[dbo].[oltp_salesorderdetail] sd
join [productdata].[dbo].[oltp_salesorderheader] sh
on sd.SalesOrderID=sh.SalesOrderID
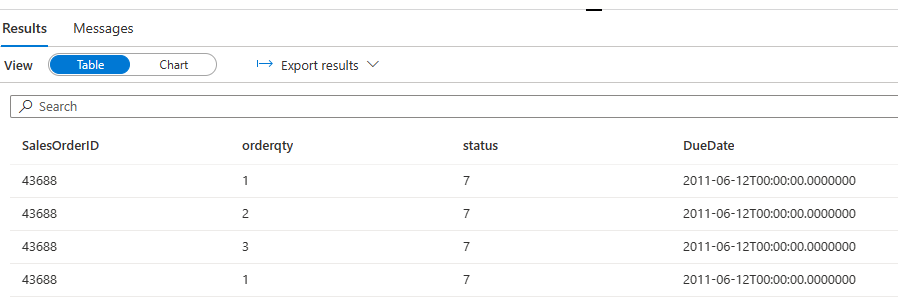
Now I can read, write,join,merge,upsert,delete etc. !!!
Note: As of today, when I am writing this, delta lake is never a 100% substitute for your RDBMS system. Delta lake will be a better candidate if you have an application which doesn’t need high concurrency transactional processing. Most of the enterprise Datawarehouse has mpp architecture hence those systems can manage concurrency very well than delta lake tables without negotiating the performance.
This is how my database diagram looks like in with couple of tables from HR and Finance department. Having said that it is easy and fun to integrate multiple departments and tables.
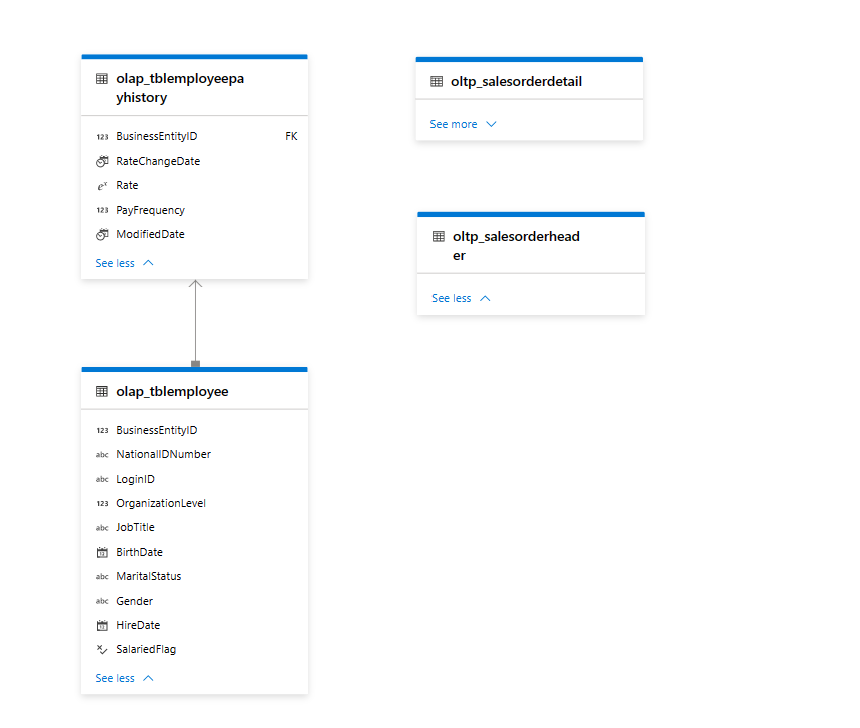
Tip: I can even create a view, procedure and function in a server less database and point to the tables created on lake database.
Thank you, Happy learning!